免責と前提本ガイドは、2026年1月時点の公開情報や一般的な実務経験をもとにまとめた「情報セキュリティ&AI活用」の参考資料です。特定の状況における法的な妥当性を保証するものではなく、法的助言(リーガルアドバイス)ではありません。機密情報の取り扱いや契約解釈については、必ず貴組織の法務・セキュリティ担当部署や弁護士などの専門家にご相談ください。
「これ入力して大丈夫?」というモヤモヤから始めよう
生成AIは、今や「使わない理由を探す方が難しい」くらい身近になりました。
- 文章の下書き
- 資料の骨子づくり
- メール文の整理
- アイデア出し・要約
……一度使い始めると、「もう手放せない」と感じる方も多いと思います。
その一方で、現場ではこんな本音もよく聞きます。
- 「便利なのは分かるけど、どこまで入れていいかが分からない」
- 「会社の情報を入れて、もし漏れたら自分の責任になりそうで怖い」
- 「AI詳しくないから、結局何が正解なの? というモヤモヤが消えない」
この記事は、そうしたモヤモヤを少しずつほどきながら、
- 「入力してもよい情報/控えるべき情報」の線引き
- 実務で使えるチェックリストと職種別のNG例
- インシデントが起きたときの考え方
- 法人向けの安全な利用環境への“移行のヒント”
をまとめた「現場目線の実務ガイド」です。
筆者自身、社内の生成AI利用ポリシーづくりや研修に関わる中で、「怖がって止めるのではなく、許容できるリスクのラインを設計する」ことの大切さを痛感してきました。
その経験も交えながら、できるだけやさしい言葉でお伝えしていきます。
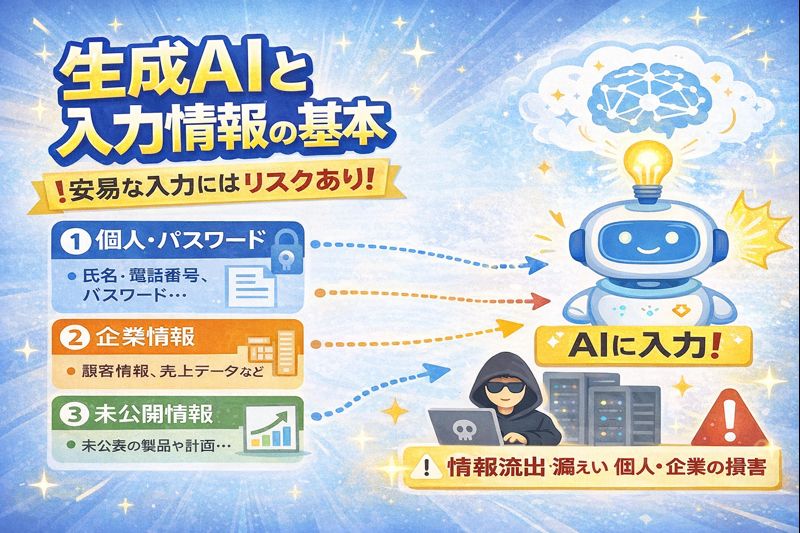
まず押さえたい「生成AIと入力情報」の基本
2-1. なぜ「入力情報」が問題になるのか?
一般的な生成AIサービスでは、次のようなことが起こり得ます。
- 入力した情報が、一定期間はサービス側のサーバーに保存される
- 利用環境によっては、モデル改善(学習)のために活用されることがある
- ログとして保管され、社内の運営担当者がアクセスできる可能性がある
すべてのサービスが同じ挙動をするわけではありませんが、多くの大規模言語モデル(LLM)では、「一度取り込んだ特定のデータだけをピンポイントで完全に消す」ことは技術的にまだ難しく、研究・改善の途中段階です。
そのため、
「間違って重要情報を入れてしまったので、完全に学習から消してください」
という要望に、将来的な再現リスクまで含めて100%応えられるとは限らない、という前提を持っておく必要があります。
これは「サービスの品質が低い」という意味ではなく、技術の性質上、完全な巻き戻しには限界がある、という冷静な理解が大切です。
2-2. 便利さとリスクの「板挟み」をどう解消するか
生成AIを禁止すれば、確かに情報漏えいリスクは減ります。
しかし同時に、こんな機会も失われます。
- 日々の資料作成コストを下げるチャンス
- 社内のナレッジを文章化・構造化するきっかけ
- 若手メンバーの「文章の型」を学ぶトレーニング機会
現場の本音は、
「使わないという選択肢は現実的じゃない。でも、事故は絶対起こしたくない。」
という板挟みの状態でしょう。
そこでこの記事では、
- 「入れても比較的リスクが低い情報」
- 「工夫すれば使えるが、慎重さが必要な情報」
- 「原則として入力を控えるべき情報」
という3つのゾーンに分けて考えることで、“ゼロか100か”ではない、現実的な運用ラインを一緒に探っていきます。
2-3. AIの回答は「便利なアシスタント」であって「最終決定者」ではない
もう一つの大事な前提が、
「AIの回答を、そのまま鵜呑みにしない」
という姿勢です。
- もっともらしいが誤った情報(ハルシネーション)
- 古い法制度やガイドラインに基づいた説明
- 特定の事例には当てはまらない一般論
といった回答が混じる可能性があります。
特に、
- 医療・健康
- 法律・税務
- 投資・保険
- 緊急性の高い相談(自傷・他害など)
に関しては、必ず専門家や一次情報での確認が必要です。
生成AIは、あくまで「考える材料」や「たたき台」を出してくれる存在であり、最終判断を代行させるべきではない、というスタンスを貫きましょう。
「入力してもよい情報」の考え方
――攻めの活用をあきらめないために「何がダメか」だけを並べると、怖くなって何も入力できなくなってしまいます。
そこで先に、“比較的リスクが低い情報”の考え方から整理しておきます。
3-1. 相対的にリスクが低いと考えられる情報の3パターン
① 一般公開されている情報(ただし利用規約には注意)
- 企業の公式サイトに掲載されているプレスリリース
- すでに一般公開されている製品・サービス情報
- メディアに掲載されたインタビュー記事 など
こうした情報は、すでに社会に公開されているため、機密性という意味では相対的にリスクが低い情報です。
ただし、
- 「転載禁止」「機械学習への利用禁止」等を定めたサイトの利用規約
- コンテンツの著作権・ライセンス条件
に反しないよう、著作権法や利用規約への配慮は必要です。
公開情報だからといって、「何に使ってもよい」わけではない
——この一線は常に意識しておきましょう。
② 個人や企業が特定できないレベルまで抽象化した情報
たとえば、
- ❌「A社のBプロジェクトで、田中さんが担当した案件の売上は3億円でした」
- ⭕「あるBtoBプロジェクトで、担当者1人あたり年間数億円規模の売上を扱うケースがあります」
というように、
- 会社名
- 個人名
- 具体的な金額や日付
などの固有名詞を外し、一般論として再構成した情報は、比較的リスクが低くなります。
ただし、ここで重要なのが「抽象化の限界」です。
氏名をイニシャルに変えただけ、部署名やプロジェクト名を少しぼかしただけ。
といった程度では、前後の文脈を組み合わせると特定されてしまうことがあります。
実務上、法的な意味での「匿名加工情報」を作るには、かなり厳密な処理やルールが必要です。
このため、重要度の高い機密情報については、抽象化しても入力を控えるという判断が安全です。
③ ダミーデータ・サンプルデータでの相談
- 架空の会社名・担当者名
- ランダムに生成した数値データ
- 実績とは無関係な架空のプロジェクト設定
など、現実の人物や企業と結び付かないサンプルデータを使って、
「こういう条件のとき、どんな切り口で提案書を考えればいい?」
といった相談をするのは、生成AIの得意分野です。
筆者が社内研修を行った際も、
- 「実データの代わりに、架空のクライアントを想定したケースで練習する」
- 「サンプル数値を使って、分析ストーリーだけをAIと一緒に組み立てる」
といった方法は、安全性と学習効果の両方で高評価でした。
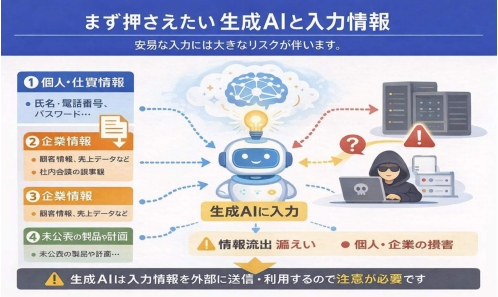
一覧で分かる
「リスクが低い」「慎重に」「原則控えるべき」情報ゾーン
判断に迷ったときのために、「相対的にリスクが低い/慎重な判断が必要/原則として入力を控えるべき」の3ゾーンに分けたイメージマップを用意しておきます。
※ 実際の表では、「○/△/×」よりも「リスク低」「要注意」「原則控える」をラベルとして使うことをおすすめします。
- リスクが比較的低い情報(工夫すれば使いやすいゾーン)
- 一般公開されている情報(利用規約に反しない範囲)
- 個人や企業が特定できないレベルまで抽象化した一般論
- 架空のデータ・サンプルデータ・ダミー設定
- 慎重な判断が必要な情報(環境・ルール次第で扱いが変わるゾーン)
- 売上データなど、数値をマスク・集計した情報
- 社内資料の一部を要約に使いたいケース
- 一般論としての技術ノウハウ(自社固有ロジックを含まない範囲)
- 原則として入力を控えるべき情報(高リスクゾーン)
- 個人が特定できる情報(氏名・住所・連絡先 等)
- 顧客リスト・具体的な取引条件・売上明細
- 社外秘資料の全文
- パスワード・APIキー・認証情報
- NDA対象データ・共同研究データ
- 特許出願前の核心部分の技術情報
さらに重要なのは、利用環境によって許容範囲が変わるという点です。
※ 個人向けの無料版か、法人契約版か、API利用かによって、入力データの保存・学習の扱いは大きく異なります。
最終的な判断は、必ず自社のルールと利用中サービスの利用規約に基づいてください。
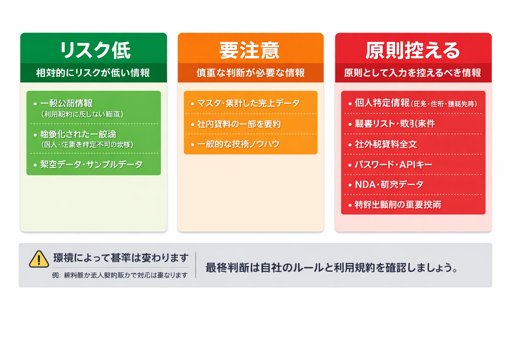
生成AIに入力してはいけない「8種類」の情報
ここからは、「原則として入力を控えるべき情報」を8つのカテゴリに分けて整理します。
5-1. 個人情報・センシティブ情報
- 氏名・住所・電話番号・メールアドレス
- 顧客ID・社員番号・会員番号などの識別子
- 生年月日や顔写真といった識別性の高い情報
- 健康・病歴・障がい・信条・家族構成など、個人の尊厳に強く関わるセンシティブ情報
日本の個人情報保護法では、こうした情報を本人の同意なく第三者に提供することに、厳しい制限があります。
生成AIの提供者に情報を送る行為は、法的に「第三者提供」とみなされる場合もあるため、業務で扱う場合は特に慎重さが求められます。
5-2. 企業の機密情報・社外秘情報
- 顧客リストや営業リスト
- 詳細な売上データ・利益率・原価情報
- 社内会議の議事録・経営会議メモ
- 取引条件が具体的に書かれた契約書案・見積書の全文
こうした情報は、企業の競争力や信頼に直結する「営業秘密」である可能性が高く、漏えいした場合の影響は計り知れません。
筆者が実際に社内ルールを作った際も、経営陣から真っ先に出てきたのは、「顧客リストと売上情報は、どんな形でも外部サービスには入れない」という強いメッセージでした。
5-3. 未公開情報・将来情報(インサイダーリスクを含むもの)
- 未発表の新製品・新サービスの具体的な仕様
- まだ公表していない人事情報(役員交代、組織再編など)
- 来期以降の業績予測や投資計画
- M&A・資本提携・上場準備といった機微情報
これらは、株価や市場に大きな影響を与え得る情報です。
証券市場のルールや自社のインサイダー取引管理規程にも関わり得るため、抽象化しても入力を控えるべき領域と考えるのが安全です。
5-4. セキュリティ関連情報(パスワード・APIキー・脆弱性など)
- パスワード・ワンタイムパスコード
- APIキー・シークレットキー・トークン
- VPN情報や管理者アカウントのID
- ネットワーク構成図・ファイアウォールの設定詳細
- 既知の脆弱性・未公開のセキュリティホール
これらは、直接的に不正アクセスやサイバー攻撃につながり得る情報です。
APIキーやパスワードの入力は、即座に不正アクセスに直結する重大なセキュリティリスクとなります。絶対に入力しないでください。
これは、社内のどんなルールよりも先に個人レベルで「絶対に守るべき鉄則」として覚えておきましょう。
5-5. 守秘義務付きの情報・預かりデータ
- NDA(秘密保持契約)の対象となっている資料やデータ
- 顧客やパートナー企業から預かった資料
- 共同研究・共同開発のために共有されたデータ
これらは、契約上の義務として厳格に守る必要がある情報です。
契約書には、
- 「再委託の可否」
- 「第三者提供の禁止」
- 「機密情報の範囲」
などが詳細に定められていることが多く、生成AIサービスへの入力が契約違反と解釈される可能性もゼロではありません。
本ガイドの内容と、個別のNDAや社内規程が食い違う場合は、必ず契約および社内規程が優先されます。
5-6. 知的財産・著作権・未公開技術
- 書籍・記事・論文など、第三者の著作物の全文
- 他社の有料コンテンツや会員限定資料
- 特許出願前の発明の核心部分
- 競合との差別化要因となる独自アルゴリズムやノウハウ
日本の著作権法では、情報解析目的の利用が一定範囲で認められていますが、多くのサービスでは利用規約で追加の制限を設けています。
また、特許出願前の技術情報を安易に外部に出してしまうと、「新規性喪失」によって権利取得が難しくなるリスクもあります。
「将来の競争力の源泉になる技術情報は、抽象化しても入れない」くらいの慎重さがちょうどよいと考えておくと安心です。
5-7. 医療・法律・税務など専門判断に直結する情報
- 個別の症状・検査値・治療歴など、詳細な医療情報
- 具体的な案件に関する法律相談の詳細
- 個人や企業の具体的な財務状況・税務スキーム
こうした内容をAIに委ねると、
- 誤ったアドバイスで健康や生活に影響が出る
- 実際の法的リスクとは異なる判断をしてしまう
- 税務上問題となるスキームを推奨される
といった危険があります。
生成AIは、専門家の代わりにはなりません。
あくまで情報整理や質問項目の洗い出しにとどめ、最終的な判断は必ず専門家に相談しましょう。
5-8. 差別的・攻撃的な内容/子ども・深刻な悩みに関する情報
- 特定の属性への差別的・攻撃的な発言
- 暴力や違法行為を肯定・助長する表現
- 子ども・未成年に関するセンシティブな情報
- 自殺・自傷・犯罪など、緊急性の高い相談内容
これらは、倫理的な観点だけでなく、プラットフォームの利用規約や各国の法制度とも密接に関わります。
深刻なメンタルヘルスの悩みや緊急性の高い状況については、オンラインのAIサービスではなく、専門窓口・医療機関・公的機関への相談が最優先です。
「これは入れていい?」を判断する5ステップ・チェックリスト
迷ったときは、次の5つの質問を順番に自問してみてください。
- 個人や企業が特定される情報を含んでいないか?
- 自社で「社外秘」や「極秘」として扱っている内容ではないか?
- NDAや契約で、第三者提供が制限されていないか?
- 著作権・商標・特許といった権利に関わる情報ではないか?
- 抽象化・ダミー化しても、文脈から特定されてしまわないか?
どこか一つでも「不安が残る」と感じたら、
- そもそも入力をやめる
- 法人向けのセキュアな環境(非学習モード等)に切り替える
- 上司・法務・情報システム部門に相談する
といった選択肢を取るのが賢明です。
7. 職種別「よくあるNGプロンプト」と安全な言い換え例
ここでは、現場で本当に起こりがちな例を、「そのままでは危ない言い方」→「安全寄りの言い換え」として紹介します。
7-1. 営業職
- ❌「A社の田中様向け見積提案文です。添付の条件を踏まえて、もっと刺さる文章に書き換えてください。」→ 顧客名+担当者名+具体条件のセットは高リスク。
- ⭕「BtoB向け営業メールのテンプレートとして、『既存顧客への追加提案』に使える文面例を作ってください。」 → 固有名詞をすべて外し、一般的なシナリオに変換して相談する。
7-2. 人事・評価・労務
- ❌「部下3名の評価コメントを貼るので、うまく整えてください。」→ 名前がなくても、社内では誰か特定される可能性が高い。
- ⭕「架空の部下3名を想定したサンプル評価コメントとして、『成長点』『課題』『期待する役割』の書き分け例を出してください。」
7-3. 開発・エンジニア
- ❌「新サービスのAPI構成とソースコードを貼るので、脆弱性がないかレビューしてください。」→ 未公開仕様・コード・脆弱性情報の三点セットは、非常に危険。
- ⭕「一般的なAPI設計におけるセキュリティ上の注意点と、よくあるアンチパターンを教えてください。」→ 具体的なコードは挙げず、設計の考え方だけを聞く。
7-4. 法務・経営企画
- ❌「このM&A検討資料のドラフトを丸ごと貼るので、リスクの抜け漏れがないか教えてください。」
- ⭕「一般的な中小企業のM&Aを想定して、 デューデリジェンスでよく確認されるリスク項目の一覧を作ってください。」
実務上、どうしても具体的資料のブラッシュアップが必要な場合は、
- 社内専用のLLM環境
- 学習に使われない法人向けプラン(Enterprise/Business/専用API環境など)
といった、契約上・技術上のセーフガードが整った環境でのみ取り扱う、というルールを徹底しましょう。
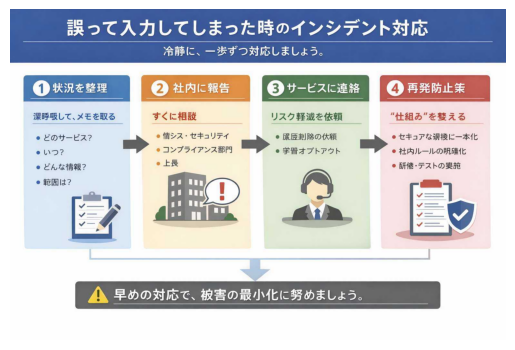
誤って入力してしまったときの「インシデント対応」
どれだけ気を付けていても、誤入力は起こり得ます。大事なのは、「起きてしまった後にどう動くか」です。
8-1. まずは深呼吸して、状況を整理する
- どのサービスに
- いつ
- どんな情報を
- どの程度の範囲で入力したか
を、思い出せる範囲でメモにまとめましょう。
8-2. 社内の相談窓口にすぐ共有する
多くの組織では、
- 情報システム部門
- セキュリティ担当チーム
- コンプライアンス部門
- 上長
のいずれかが、インシデント対応の窓口となっています。
「こんなことをしてしまったら怒られるのでは?」という不安から、報告を先延ばしにするのが一番危険です。
早期に共有するほど、影響を小さくできる可能性が高まります。
8-3. サービス提供者への問い合わせを検討する
一部のサービスでは、
- チャット履歴の削除
- モデル改善への利用停止(オプトアウト)
などの手続きが用意されています。
完全な削除や学習からの除外を保証できるわけではありませんが、可能な範囲でリスクを軽減する対応として、社内の担当部署と相談しながら進めましょう。
8-4. 再発防止策を“仕組み”として整える
- 無料版ではなく、法人向けのセキュアな環境に一本化する
- 「入力禁止情報リスト」を社内規程に明記する
- 具体例ベースのeラーニング・テスト・研修を実施する
筆者の経験上、「禁止事項だけをメールで配る」ルールは、残念ながら定着しにくいことが多いです。
- 「どこまでがOKなのか」の線引きをセットで伝える
- NG例→安全な言い換えをセットで見せる
- 上司自身が率先してルールを守る姿を見せる
といった工夫が、組織全体の“AIリテラシー”を底上げしていきます。
法律・ガイドラインと生成AI:最低限押さえておきたいポイント
詳細な法解説は専門書に譲るとして、ここでは生成AI利用と関わりが深いキーワードをいくつか挙げておきます。
- 日本の個人情報保護法:
個人情報・個人データ・要配慮個人情報・匿名加工情報などの定義 - 個人情報保護委員会(PPC)によるAI・クラウド利用に関する注意喚起
- 経済産業省・総務省などが公表しているAIガバナンス関連の指針
- 文化庁による著作権とAIに関する考え方
- 欧州で進むEU AI Actなど、国際的なAI規制の動き
こうした一次情報は、随時アップデートされていきます。
本ガイドは、これらの公的資料に沿った「考え方の整理」を目的としています。
最終的な判断は、必ず最新のガイドラインや自組織の規程に基づいてください。
安全にAIを活用するための「環境」と「設計」の考え方
2026年現在、多くの主要サービスでは、法人向けプランや専用環境が整備されてきています。
10-1. 無料版と法人向け環境の大きな違い
一般的に、法人向けプランでは、
- 入力データをモデル学習に利用しないことを契約上明示
- データの保管場所やアクセス権限の管理が厳格
- ログ・監査・権限管理の機能が充実
といった特徴があります。
筆者が社内相談に乗る際も、「機密度の高い情報を扱うチームは、最初から無料版ではなく法人向け環境を前提にする」という方針を強くおすすめしています。
10-2. 社内ルール・ポリシーをどう作るか
社内ポリシーを作るときは、最低限次の要素を盛り込みます。
- 利用目的(何のためにAIを使うのか)
- 入力してはならない情報の具体例リスト
- 利用してよい環境(サービス名・プラン・利用方法)
- インシデントが発生した場合の報告フロー
- 定期的な見直し・教育の方法
この記事で紹介したOK/注意/原則控えるの3ゾーンや8種類のNGカテゴリは、そのままポリシー案のたたき台として活用できます。
10-3. 個人・チーム・組織の3レイヤーで考える
最後に、「誰がどこまで責任を持つか」という視点です。
- 個人:
自分が扱う情報の機密度を理解し、
この記事のチェックリストに沿って入力可否を判断する。 - チーム(部署):
業務の性質に応じて、
「どのタスクはAIに任せてよいか/ダメか」を整理し共有する。 - 組織全体:
法務・情シス・経営層が連携し、
「環境」「ルール」「教育」「インシデント対応」を包括的に設計する。
生成AIの活用は、一人ひとりの注意と、組織としての設計の両輪があって初めて安全に回るものです。
まとめ:生成AI時代に「守るべき情報」をどう設計するか
- リスクを完全にゼロにすることは現実的ではありません。
- だからこそ、
- 「相対的にリスクが低い情報」
- 「慎重な判断が必要な情報」
- 「原則として入力を控えるべき情報」
を意識的に分けて考えることが大切です。
- 無料版の便利さだけで判断せず、
法人向けのセキュアな環境への移行や社内ルール整備を進めることで、
生成AIは「怖いもの」から「頼れる相棒」に変わっていきます。
この記事が、あなたやあなたの組織にとっての「AI活用と情報保護の羅針盤」になれば幸いです。
本ガイドは 2026年1月時点 の情報をもとに作成しています。
AIサービスや法制度、各社の利用規約は変化し続けるため、必ず最新の一次情報(公的機関・公式ドキュメント・自社規程)を確認しながら運用してください。
また、個別の契約(NDA・業務委託契約など)や社内規程が本ガイドと異なる場合は、常に契約および社内規程が優先されます。


コメント